
Not so fast! I’m assuming that you have read already about GraphQL. If not, I highly recommend to read a GraphQL introduction or watch a great talk first.
Use Case
A few months ago I started together with my great teammates on building an API for one of our clients. The website that needs information from this API is done by a different party. If I had to summarise the technical requirements for this API, I would include these points:
- Performant fetching of all content needed for a single webpage
- All content is user-specific
- The content is highly connected
- Exposing more content should be easily possible
- The API should be reusable for many API consumers
- Maintainable for many years
Can you make a REST-API that fulfils these requirements? Probably. But there is a more efficient, better suited alternative.
GraphQL is better than REST?
Traditionally we are used to building RESTful APIs, but after a careful evaluation with all involved parties we decided to go for GraphQL. This turned out to be great – here is why.
- Only the content that is needed by the website is returned
This reduces network traffic compared to a REST approach where mostly too much content is returned (overfetching). - All content for a single webpage can be fetched in one request
Making many API requests to fetch all content for a webpage (underfetching) can lead to performance issues. With GraphQL there is only one request. - Less coordination needed between API and website parties
Exposing more content is a few line of configuration code. The new content is immediately accessible by the website. There is no need for communication on which endpoints data needs to be made available. - Total flexibility for API consumers
Different API consumers have different needs. To make content fetching performant, one might build specialised REST endpoints that return exactly the information a API consumer needs which is costly and brittle. - GraphQL Schema
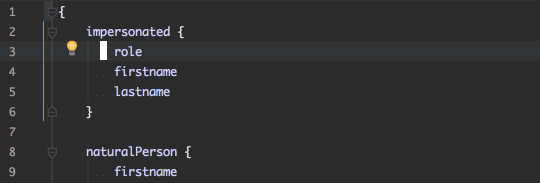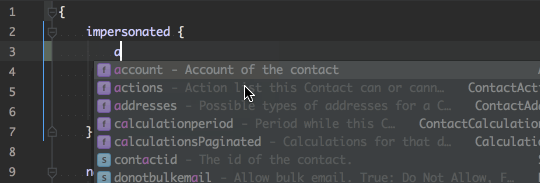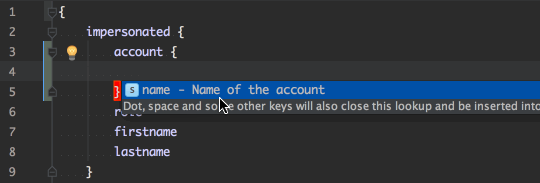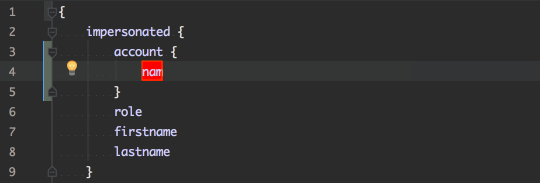
The schema enables tools to do auto-complete and detect on compile time that a request will work (or not). This reduced development time. See the PHPStorm integration:
- Documentation is embedded in the schema
This is nice because the documentation is right in the editor instead of on a separate documentation website like with REST. - Versioning is not an issue
Deprecating fields and providing an update path is easy. So much easier than providing proper versioning in REST. - Smart client-side caching
User-specific content makes it hard to achieve a good cache-hit rate using HTTP cache methods. Based on the GraphQL schema there can be intelligent client side caching which knows what data is available and what needs to be fetched. - Efficient changes
GraphQL also supports changes, they are called mutations. Mutations can be batched (multiple mutations) and even fetch content in the same request.
Summarising
With every new technology there are certain risks involved when adopting it. I want to build solutions for clients that provide lots of value and are cost efficient. With GraphQL in this case I think we delivered a better solution than the traditional REST API. I expected to run into more issues with our first project in GraphQL but so far it went quite smooth.
As always, you have to consider the tradeoffs when adopting technology for your own use case. If you consider using GraphQL or if you have questions please let me know in the comments or via Twitter. I’m interested in your findings.
